Joint Segmentation/Clustering of movement data. Method available for data.frame, move and ltraj objects. The algorithm finds the optimal segmentation for a given number of cluster and segments using an iterated alternation of a Dynamic Programming algorithm and an Expectation-Maximization algorithm. Among the different segmentation found, the best one can be chosen using the maximum of a BIC penalized likelihood.
segclust(x, ...)
# S3 method for data.frame
segclust(x, ...)
# S3 method for Move
segclust(x, ...)
# S3 method for ltraj
segclust(x, ...)Arguments
- x
data.frame with observations
- ...
additional parameters given to
segclust_internal.
Value
a segmentation-class object
Examples
#' @examples
df <- test_data()$data
#' # data is a data.frame with column 'x' and 'y'
# Simple segmentation with automatic subsampling
# if data has more than 1000 rows:
res <- segclust(df,
Kmax = 15, lmin = 10, ncluster = 2:4,
seg.var = c("x","y"))
#>
#> ── Checking arguments ──────────────────────────────────────────────────────────
#> ✔ Segmentation with seg.var = c("x", "y")
#> ✔ Using lmin = 10
#> ✔ Using Kmax = 15
#> ✔ Using ncluster = 2:4
#> ! Argument scale.variable missing
#> Taking default value scale.variable = TRUE for segclust().
#> ℹ Argument diag.var was not provided
#> Taking default seg.var as diagnostic variables diag.var.
#> Setting diag.var = c("x", "y")
#> ℹ Argument order.var was not provided
#> Taking default diag.var[1] as ordering variable order.var.
#> Setting order.var = "x"
#>
#> ── Preparing and checking data ─────────────────────────────────────────────────
#>
#> ── Subsampling ──
#>
#> ! Subsampling automatically activated. To disable it, provide subsample = FALSE
#> ℹ Argument subsample_over was not provided
#> Taking default value for segmentation()
#> Setting subsample_over = 10000
#> ✔ nrow(x) < subsample_over, no subsample needed
#>
#> ── Scaling and final data check ──
#>
#> ✔ Rescaling variables.
#> To deactivate, use scale.variable = FALSE
#> ✔ Data have no repetition of nearly-identical values larger than lmin
#>
#> ── Running Segmentation/Clustering algorithm ───────────────────────────────────
#> ℹ Running Segmentation/Clustering with lmin = 10, Kmax = 15 and ncluster = 2:4
#> → Calculating initial segmentation without clustering
#> ✔ Initial segmentation with no cluster calculated.
#> → Calculating initial segmentation without clustering
#>
#> → Calculating initial segmentation without clustering
#> ── Segmentation/Clustering with ncluster = 2
#> → Calculating initial segmentation without clustering
#> → Calculating initial segmentation without clustering
#> → Segmentation-Clustering for ncluster = 2 and nseg = 2/15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 3/15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 4/15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 5/15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 6/15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 7/15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 8/15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 9/15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 10/15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 11/15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 12/15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 13/15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 14/15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 15/15
#> ✔ Segmentation-Clustering successful for ncluster = 2 and nseg = 2:15
#> → Segmentation-Clustering for ncluster = 2 and nseg = 15/15
#> → Smoothing likelihood for ncluster = 2. This step can be lengthy.
#> ✔ Smoothing successful for ncluster = 2
#> → Smoothing likelihood for ncluster = 2. This step can be lengthy.
#> → Calculating initial segmentation without clustering
#> ✔ Segmentation/Clustering with ncluster = 2 successfully calculated.
#> BIC selected : nseg = 4
#> → Calculating initial segmentation without clustering
#>
#> → Calculating initial segmentation without clustering
#> ── Segmentation/Clustering with ncluster = 3
#> → Calculating initial segmentation without clustering
#> → Calculating initial segmentation without clustering
#> → Segmentation-Clustering for ncluster = 3 and nseg = 3/15
#> → Segmentation-Clustering for ncluster = 3 and nseg = 4/15
#> → Segmentation-Clustering for ncluster = 3 and nseg = 5/15
#> → Segmentation-Clustering for ncluster = 3 and nseg = 6/15
#> → Segmentation-Clustering for ncluster = 3 and nseg = 7/15
#> → Segmentation-Clustering for ncluster = 3 and nseg = 8/15
#> → Segmentation-Clustering for ncluster = 3 and nseg = 9/15
#> → Segmentation-Clustering for ncluster = 3 and nseg = 10/15
#> → Segmentation-Clustering for ncluster = 3 and nseg = 11/15
#> → Segmentation-Clustering for ncluster = 3 and nseg = 12/15
#> → Segmentation-Clustering for ncluster = 3 and nseg = 13/15
#> → Segmentation-Clustering for ncluster = 3 and nseg = 14/15
#> → Segmentation-Clustering for ncluster = 3 and nseg = 15/15
#> ✔ Segmentation-Clustering successful for ncluster = 3 and nseg = 3:15
#> → Segmentation-Clustering for ncluster = 3 and nseg = 15/15
#> → Smoothing likelihood for ncluster = 3. This step can be lengthy.
#> ✔ Smoothing successful for ncluster = 3
#> → Smoothing likelihood for ncluster = 3. This step can be lengthy.
#> → Calculating initial segmentation without clustering
#> ✔ Segmentation/Clustering with ncluster = 3 successfully calculated.
#> BIC selected : nseg = 6
#> → Calculating initial segmentation without clustering
#>
#> → Calculating initial segmentation without clustering
#> ── Segmentation/Clustering with ncluster = 4
#> → Calculating initial segmentation without clustering
#> → Calculating initial segmentation without clustering
#> → Segmentation-Clustering for ncluster = 4 and nseg = 4/15
#> → Segmentation-Clustering for ncluster = 4 and nseg = 5/15
#> → Segmentation-Clustering for ncluster = 4 and nseg = 6/15
#> → Segmentation-Clustering for ncluster = 4 and nseg = 7/15
#> → Segmentation-Clustering for ncluster = 4 and nseg = 8/15
#> → Segmentation-Clustering for ncluster = 4 and nseg = 9/15
#> → Segmentation-Clustering for ncluster = 4 and nseg = 10/15
#> → Segmentation-Clustering for ncluster = 4 and nseg = 11/15
#> → Segmentation-Clustering for ncluster = 4 and nseg = 12/15
#> → Segmentation-Clustering for ncluster = 4 and nseg = 13/15
#> → Segmentation-Clustering for ncluster = 4 and nseg = 14/15
#> → Segmentation-Clustering for ncluster = 4 and nseg = 15/15
#> ✔ Segmentation-Clustering successful for ncluster = 4 and nseg = 4:15
#> → Segmentation-Clustering for ncluster = 4 and nseg = 15/15
#> → Smoothing likelihood for ncluster = 4. This step can be lengthy.
#> ✔ Smoothing successful for ncluster = 4
#> → Smoothing likelihood for ncluster = 4. This step can be lengthy.
#> → Calculating initial segmentation without clustering
#> ✔ Segmentation/Clustering with ncluster = 4 successfully calculated.
#> BIC selected : nseg = 6
#> → Calculating initial segmentation without clustering
#>
#> ── Segmentation/Clustering results ─────────────────────────────────────────────
#> ✔ Best segmentation/clustering estimated with 3 clusters and 6 segments according to BIC
#> → Number of cluster should preferentially be selected according to biological
#> knowledge. Exploring the BIC plot with plot_BIC() can also provide advice to
#> select the number of clusters.
#> → Once number of clusters is selected, the number of segment cab be selected
#> according to BIC.
#> → Results of the segmentation/clustering may further be explored with plot()
#> and segmap()
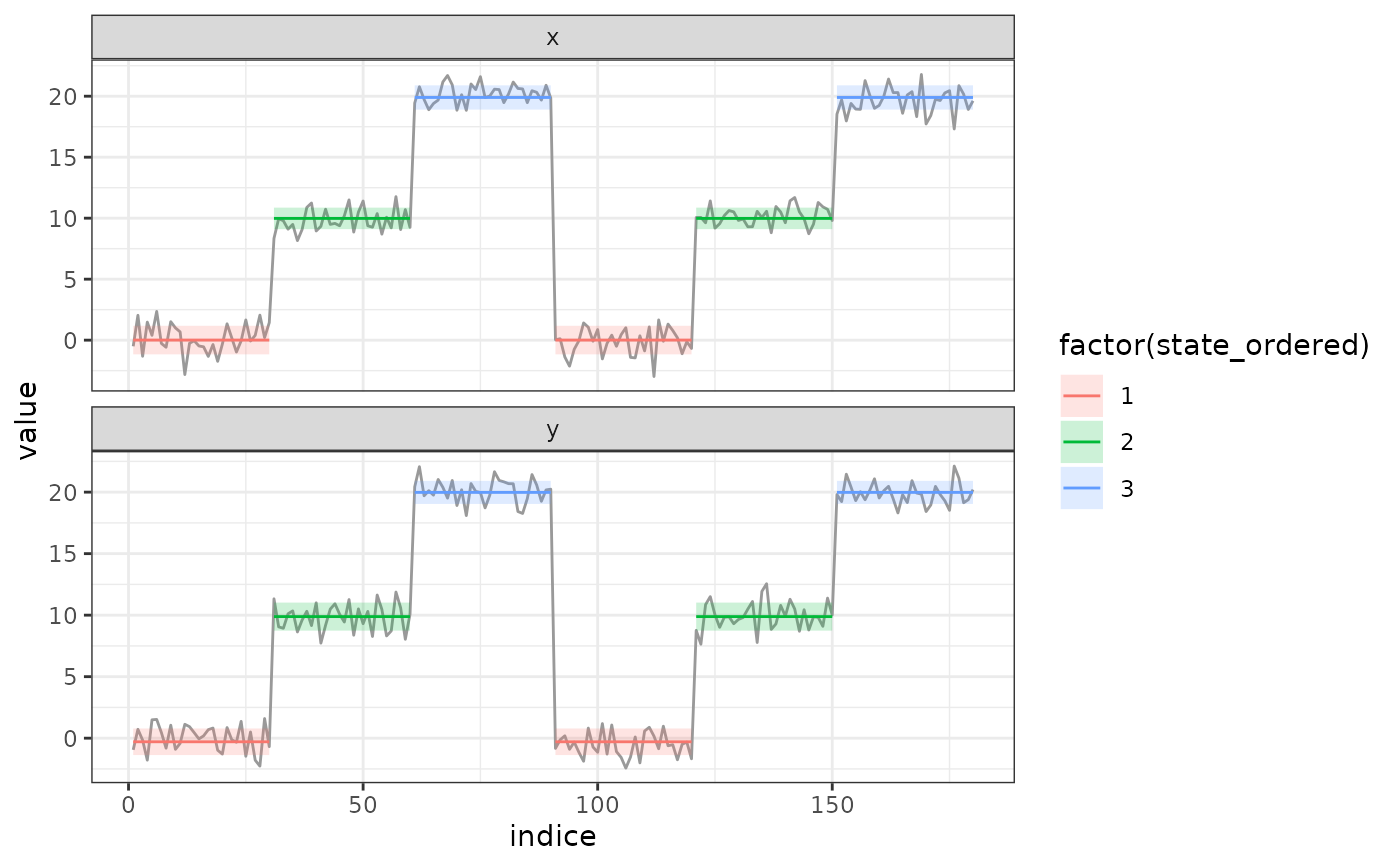
# Plot results
plot(res)
#> ℹ Argument order missing.
#> Ordering cluster with variable x for segmentation/clustering. To disable, use
#> order = FALSE
#> ! Argument ncluster was not provided. Selecting values with BIC
#> ℹ BIC-selected number of class : ncluster = 3
#> BIC-selected number of segment : nseg = 6
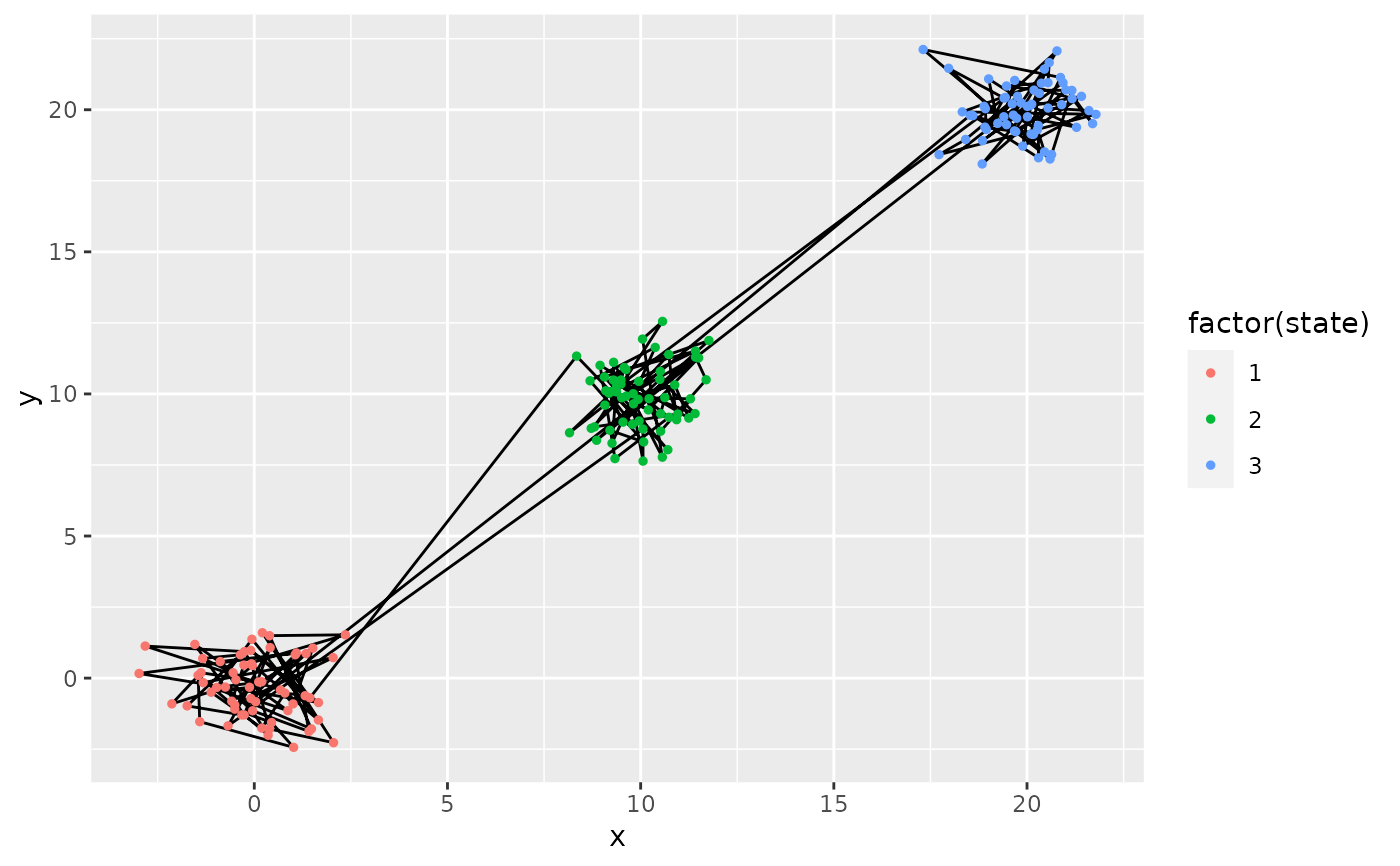
 segmap(res, coord.names = c("x","y"))
#> ℹ Argument order missing.
#> Ordering cluster with variable x for segmentation/clustering. To disable, use
#> order = FALSE
#> ! Argument ncluster was not provided. Selecting values with BIC
#> ℹ BIC-selected number of class : ncluster = 3
#> BIC-selected number of segment : nseg = 6
segmap(res, coord.names = c("x","y"))
#> ℹ Argument order missing.
#> Ordering cluster with variable x for segmentation/clustering. To disable, use
#> order = FALSE
#> ! Argument ncluster was not provided. Selecting values with BIC
#> ℹ BIC-selected number of class : ncluster = 3
#> BIC-selected number of segment : nseg = 6
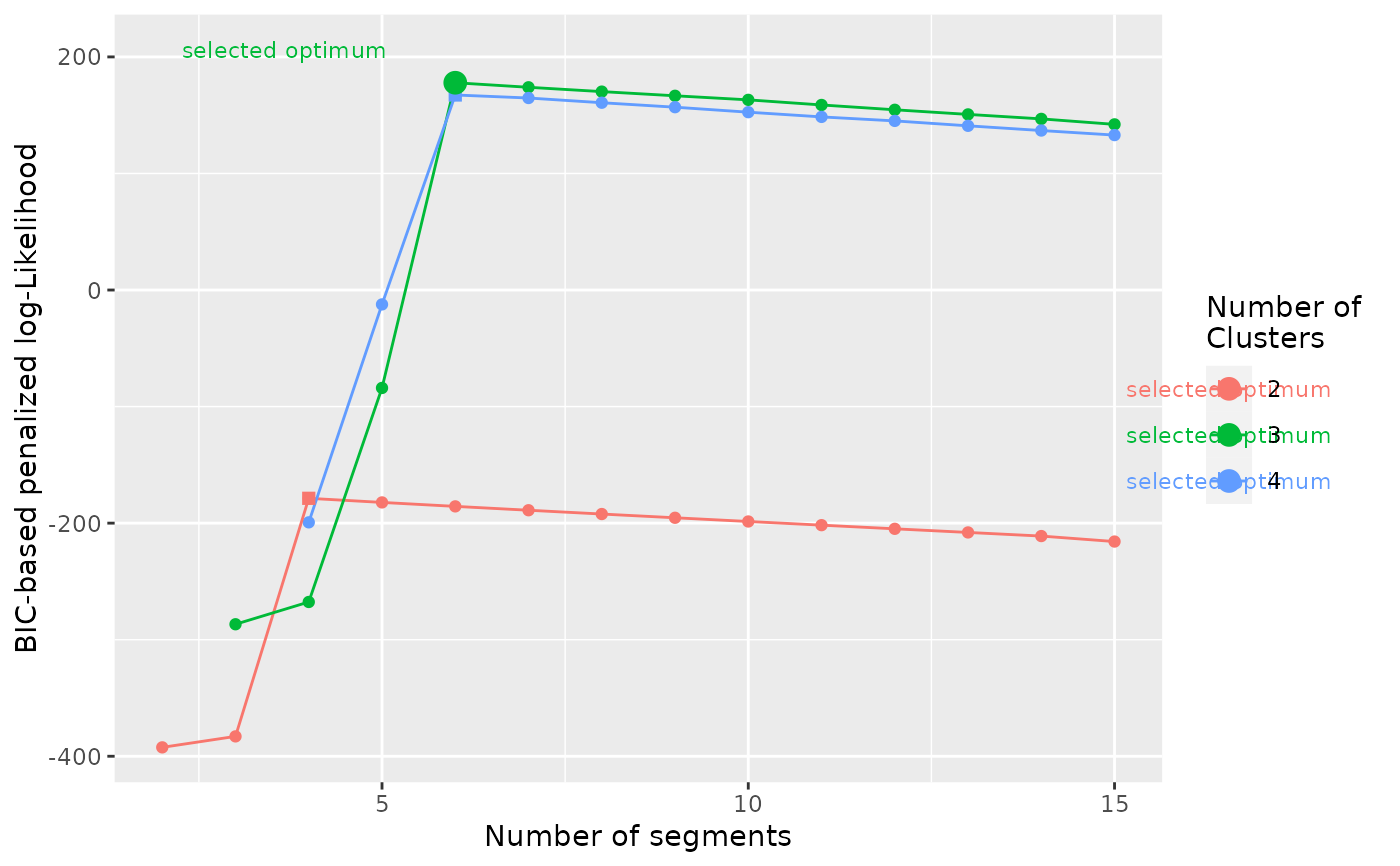
 # check penalized likelihood of
# alternative number of segment possible.
# There should be a clear break if the segmentation is good
plot_BIC(res)
# check penalized likelihood of
# alternative number of segment possible.
# There should be a clear break if the segmentation is good
plot_BIC(res)
 if (FALSE) {
# Advanced options:
# Run with automatic subsampling if df has more than 500 rows:
res <- segclust(df, Kmax = 30, lmin = 10, ncluster = 2:4,
seg.var = c("x","y"), subsample_over = 500)
# Run with subsampling by 2:
res <- segclust(df, Kmax = 30, lmin = 10, ncluster = 2:4,
seg.var = c("x","y"), subsample_by = 2)
# Disable subsampling:
res <- segclust(df, Kmax = 30, lmin = 10,
ncluster = 2:4, seg.var = c("x","y"), subsample = FALSE)
# Disabling automatic scaling of variables for segmentation (standardazing
# the variables) :
res <- segclust(df, Kmax = 30, lmin = 10,
seg.var = c("dist","angle"), scale.variable = FALSE)
}
if (FALSE) {
# Advanced options:
# Run with automatic subsampling if df has more than 500 rows:
res <- segclust(df, Kmax = 30, lmin = 10, ncluster = 2:4,
seg.var = c("x","y"), subsample_over = 500)
# Run with subsampling by 2:
res <- segclust(df, Kmax = 30, lmin = 10, ncluster = 2:4,
seg.var = c("x","y"), subsample_by = 2)
# Disable subsampling:
res <- segclust(df, Kmax = 30, lmin = 10,
ncluster = 2:4, seg.var = c("x","y"), subsample = FALSE)
# Disabling automatic scaling of variables for segmentation (standardazing
# the variables) :
res <- segclust(df, Kmax = 30, lmin = 10,
seg.var = c("dist","angle"), scale.variable = FALSE)
}